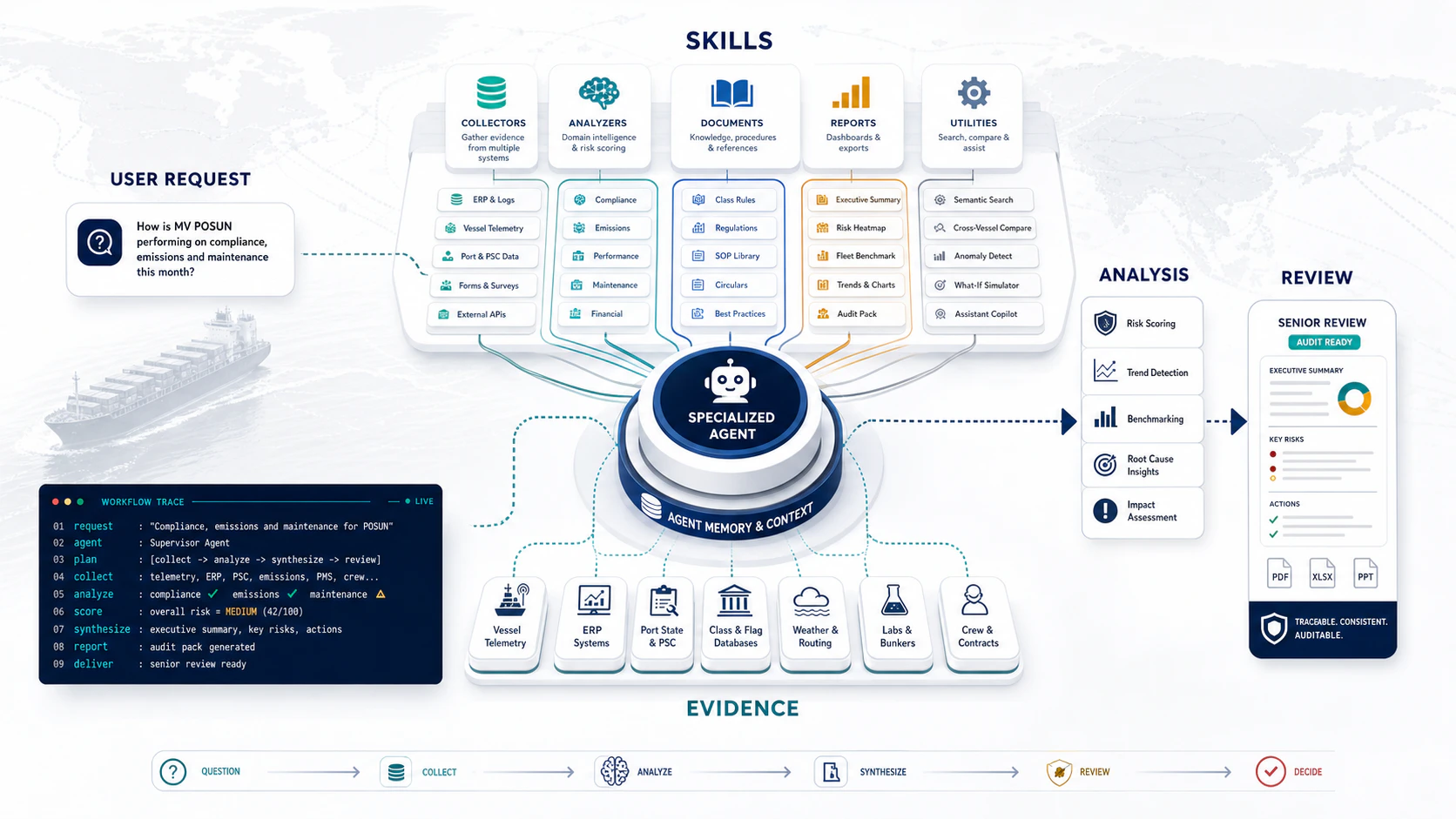
What skills are
Skills are modular, reusable capabilities that agents invoke to do real work. Each skill packages a workflow — what it reads, what it produces, when to use it — into a portable unit any agent can call. The same skill works equally well for a senior agent reviewing a vessel and a human operator running a one-off check. The library currently has 44 skills grouped into four areas: collectors that gather evidence, analyzers that turn that evidence into senior reviews, document tools that index and search the maritime knowledge base, and utilities for reports, images, and intelligence queries.How skills compose
Most maritime work follows a two-stage pattern:- A data collector fetches the latest evidence for a vessel domain (engine telemetry, certificates, defects, etc.) and files it as a timestamped, append-only record.
- An analyzer reads that evidence, runs a deterministic analysis script, and produces a senior expert review with prioritised actions and an escalation decision.
Categories
Collectors — gather evidence
Per-vessel data collectors that snapshot a single domain:- AE Performance, ME Performance, ME Microapp — engine telemetry
- Fuel Oil, Lube Oil, Water Treatment — fluids and chemistry
- Certificates, Class Society, Compliance — regulatory and class
- Crew, PMS, Defects — manning and maintenance
- Voyage, Purchase, Financial, Forms — operations and admin
- CII / Emissions — emissions microapp evidence with screenshots
Analyzers — produce senior reviews
Senior agents that turn collector evidence into TSI-grade reviews with escalation logic:- AE Performance, ME Performance — engine reviews with SFOC variance, blackout risk, overhaul timing
- Fuel Oil, Lube Oil, Water Treatment — fluid and chemistry reviews
- Certificates, Class Society, Compliance — detention-risk and compliance
- Crew, PMS, Defects — manning, maintenance, defect reviews
- Voyage, Purchase, Financial, Forms — operations, procurement, budget reviews
Documents & knowledge
Tools that turn the maritime corpus into searchable, citable knowledge:- Search Indexed Documents — search circulars, IMPA, IMO, manuals with exact-quote evidence
- PDF to Markdown — bulk convert PDFs to searchable markdown with embedded page images
- PDF Vision Extractor — high-accuracy tiled extraction for diagrams and tables
- Download Flag Circulars, Download Makers Circulars — keep the corpus current
- Vessel Intelligence — query and write observations, notes, and learnings linked to cases
- Outlook Email Sync — sync mailbox into a searchable local index
Reports & utilities
Cross-cutting tools used during inspections, investigations, and reporting:- Maritime Report Generator — turns inspection photos + vessel data into polished VIR / Owner’s / Incident reports
- QHSE Investigation Report — cross-domain Quality, Health, Safety, Environment investigation
- Image Analysis — vessel-mode equipment classification or general-mode description
- Image Generator — AI image generation
- Validate Consumption Log Data — pre-upload data quality check for CII, EU MRV, IMO DCS, FuelEU